Whenever we work on database optimization, the first solution that comes to mind is using indexes, right? It’s kind of a silver bullet that solves every performance bottleneck for us, until it harms us in an unexpected way. If you fall into that situation, it’s really hard to figure out what happened because it requires deep knowledge of databases to understand the root cause. After a year of learning, I can finally understand and resolve a mysterious problem I faced before at When index scan is slower than full table scan
Quick Recall
We have a table with more than two million records:
SELECT count(id) FROM products
-- count(id): 2281099
We were using a query like this, which was very slow even though we had an index on the column we were filtering:
EXPLAIN ANALYZE SELECT p.user_id
FROM products AS p
WHERE p.active
GROUP BY p.user_id;
---> Limit: 200 row(s) (cost=5086.80 rows=200) (actual time=31904.827..37635.793 rows=8 loops=1)
-- -> Group (no aggregates) (cost=5086.80 rows=33925) (actual time=31904.825..37635.788 rows=8 loops=1)
-- -> Filter: (0 <> p.active) (cost=1587.60 rows=33925) (actual time=28788.416..37635.374 rows=825 loops=1)
-- -> Index scan on p using IX_products_user_id (cost=1587.60 rows=37694) (actual time=38.097..37491.597 rows=2281100 loops=1)
But the weird thing happened when we ignored the index and used a full table scan—the query ran faster:
EXPLAIN ANALYZE SELECT p.user_id
FROM products AS p USE INDEX () -- ignore all index, only available in MySQL
WHERE p.active
GROUP BY p.user_id;
-- -> Limit: 200 row(s) (cost=446934.14..446936.62 rows=200) (actual time=1152.400..1152.402 rows=8 loops=1)
-- -> Table scan on <temporary> (cost=0.01..25337.80 rows=2026824) (actual time=0.002..0.003 rows=8 loops=1)
-- -> Temporary table with deduplication (cost=446934.14..472271.92 rows=2026824) (actual time=1152.399..1152.401 rows=8 loops=1)
-- -> Filter: (0 <> p.active) (cost=244251.70 rows=2026824) (actual time=0.285..1151.343 rows=825 loops=1)
-- -> Table scan on p (cost=244251.70 rows=2252027) (actual time=0.071..1021.024 rows=2281105 loops=1)
Explaination
Before getting into the details, there’s an important statistic I want to share with you:
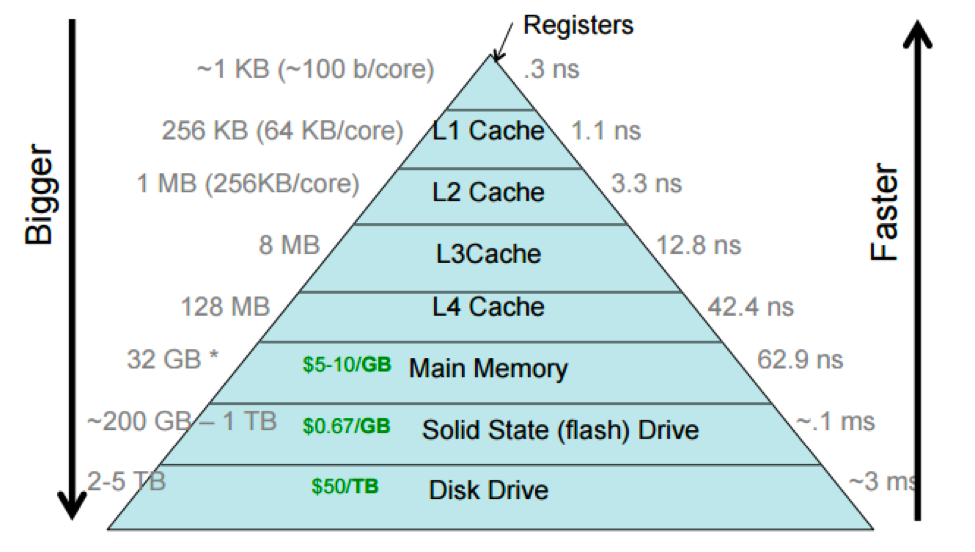
The key takeaway is that RAM is 1,600 times faster than SSD. Why does this matter? Because one of the main goals of database optimization is to minimize disk I/O as much as possible.
To achieve this, the database splits your data into small chunks: they are called blocks on disk and pages in memory. By breaking the data into smaller parts, the database can efficiently cache frequently accessed data in memory, which leads to better read performance. The following image shows a simplified version of the database storage structure.
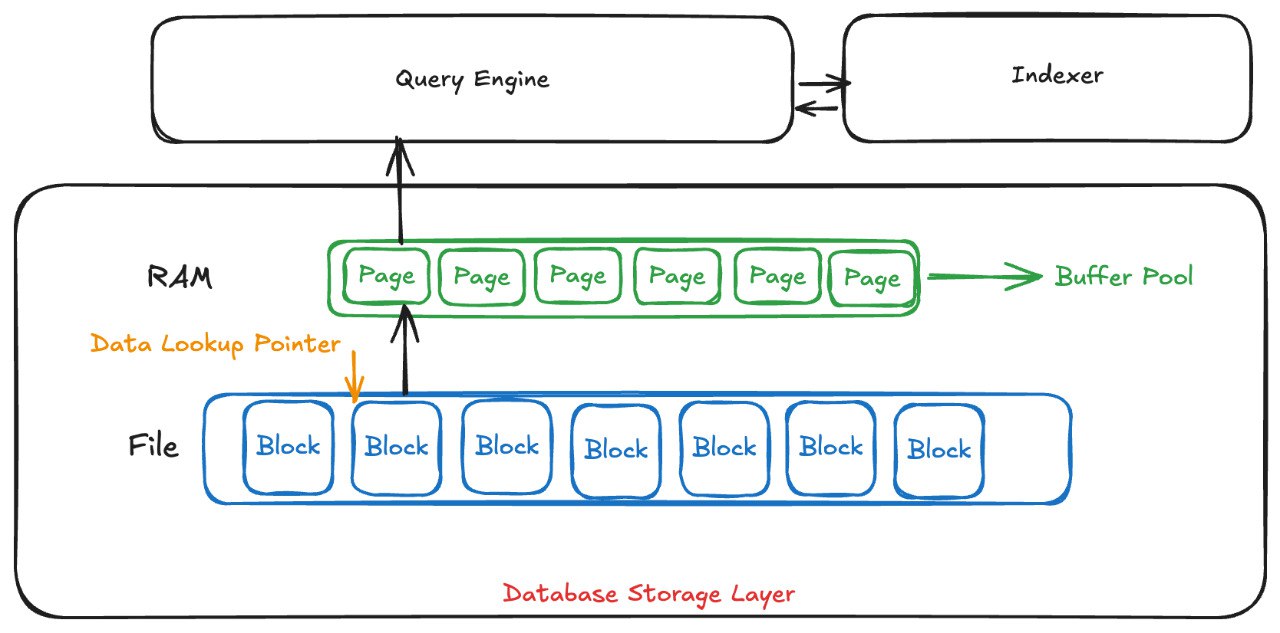
Whenever you query a row in a database, it first checks whether the requested data already exists in the buffer pool. If it doesn’t, the database needs to look it up in the file on disk. The problem is that the database has to find exactly where the block containing your data is located, it has to open the target file and navigate to the correct offset to retrieve the data. This process is costly because it requires multiple I/O operations to complete. This isn’t a big issue when you only need a few I/O operations to retrieve some records compared to reading all the database files for the same amount of data.
But imagine you need to query around 80% of the data in your database. You would have to travel through the B-Tree index, open files, and navigate to the correct offsets to get the data blocks. This happens millions of times in such a case and becomes the root cause of the slow query.
When you use a table scan, the database knows it can safely ignore the index. It only needs to open files one by one, loop through all the blocks, and use them. In this case, the number of I/O operations is much smaller than in the previous scenario because one file can contain many blocks, depending on the database configuration. So you only need to perform thousands of I/O operations instead of millions.
Conclusion
The main purpose of a database is … to store data, so understanding how data is organized and retrieved is critical for our life as developers. I will continue learning about databases, not just storage but also other aspects such as WAL, transactions, partitions, and more.