In previous blog post titled The art of Export, I covered various aspects of the exporting data. In this post, we will discuss about the oposite workflow: importing data. The solution chosen for importing will be effected by a critical component - the storage - because without storage you would have to recieve data chunks directly from clients. This would blocks your APIs from handling other requests and degrade your system’s performance, especially if you don’t use data streaming in your programming language. That why haveing a storage storage system that can handle uploading robustly is a requirement to get deep into my solution. If you are developing your system on cloud, you can easily find an appropriate storage solution from your provider, such as S3 on AWS or Cloud Storage on GCP.
Implementation
There is a diagram that describes the workflow of my solution, which consists of three parts. First, the client makes a request for an upload URL and an Import ID which they will use to upload their heavy file and check the task status later. Second, after the file is successfully uploaded, a trigger message is fired, and a worker will listen to that event. The worker has the responsibility to do every optimization to make the import as fast as posible and update the task’s status into the database once the import is completed. Finally, the client repeatedly checks the task’s status until it is completed (either succesfully or unsuccessfully).
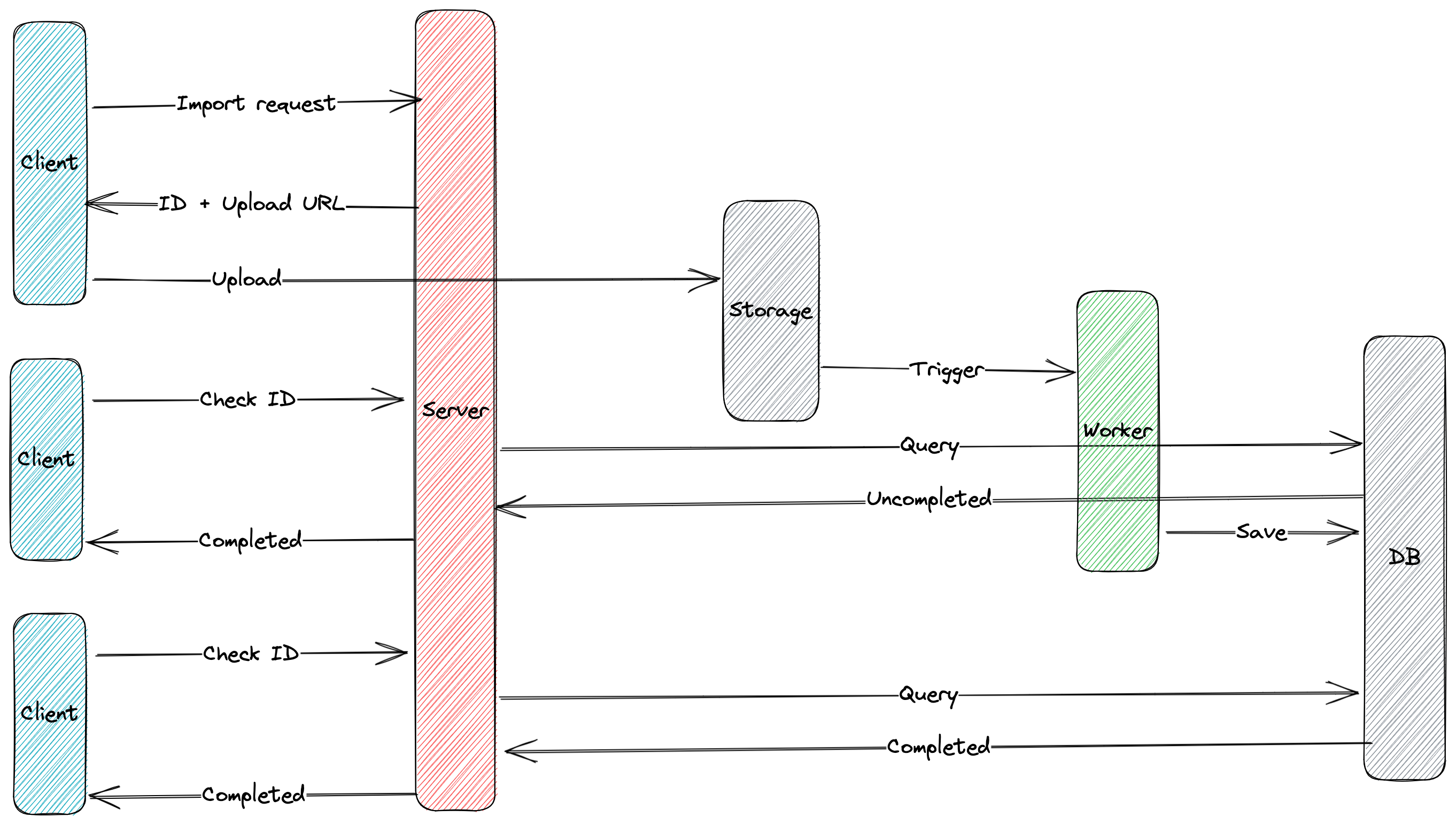
Request an import task
In this step, the client makes a request ask for a pre-signed URL to upload their file and an import ID to check their task status. The pre-signed URL is a specific feature of cloud storage that limits what scopes can be performed with the given URL. For example, you can request a URL that is signed under your account with only two properties: content type and upload method, which restricts the scope of what can be uploaded to the URL. Any other combination of properties will be rejected to protect your URL. Once the client has the upload URL, they can upload their file and wait for the upload progress to be completed.
Trigger upload completed event
Cloud storage services (i.e., AWS and GCP) often support event firing when a file is uploaded successfully. This makes it easy to automate the import process by listening to that event and triggering the import action. However, if your cloud storage does not support event firing, you have to require the client to call another API to inform the server that they have finished uploading the file. Then, the server can fire an event to let the worker know they can start carrying out the import action. Once import action is completed, the worker updates the task status in database so that the client can query it later.
You can see how important good cloud storage is showed here. Without it, you have to deal with uploading large files when the connection is unstable, as well as dealing with event firing when something happens to that file. This would make your implementation more complex and difficult to maintain. Therefore, I strongly suggest that you choose a cloud storage and start using it. You may want to consider AWS S3, min.io or Backblaze.
Checking task status
We will use pulling model, as we did in The art of Export, to check status of the import task. The different lies in what the client receives after the task is successfully completed. Instead of receiving both task status and a URL in the response, the client is only receive the status. This mean the client only needs to inform the user that the import task is done, and it is safeto continue working with the imported data.
Technical decisions
There aren not many technical decisions to consider regarding this topic since we have already chosen the most important component in this topic - storage. Therefore, I will only provide you with some storage providers to consider based on your use case
- AWS S3 is reliable service that is widely known. It is easily to integrate into your system using various programming language without much hassle.
- If you want to use the S3 API but with a lower price, then min.io and Backblaze are other options worth considering.
- If your infrastructure is heavily dependent on Google Cloud, the Google Cloud Storage is an excellent option to explore