Almost every system has a dataflow that involves exporting entities for various purposes. Having worked with these systems for eight years, I have encountered a variety of ways to implement them, but none have made me entirely satisfied. Some are easy to implement, but they don’t perform well at larger scales, while others are effective solutions that work well at any data size, but are not straightforward. For example
- A performance-focused approach involves creating an export request and returning a task ID that allows the client to use a real-time connection to check the task status and download URL.
- On the other hand, a feasibility-focused approach entails making some queries, transforming them in memory, then streaming the results to the client. However, the more items that need to be exported, the more memory is required
Today, I want to introduce to everyone a solution that I have been using for a long time, which strikes a balance between performance and feasibility.
Implementation
Allow me to show you the diagram of my wonderful export workflow, which consists of three parts. First, the client submits their query criteria to request an export task. Second, a background job system handles the heavy lifting and updates the task’s status, progress and resources (i.e., download URL) into a database. Finally, the client repeatedly checks the task’s status until it is completed (either succesfully or unsuccessfully)
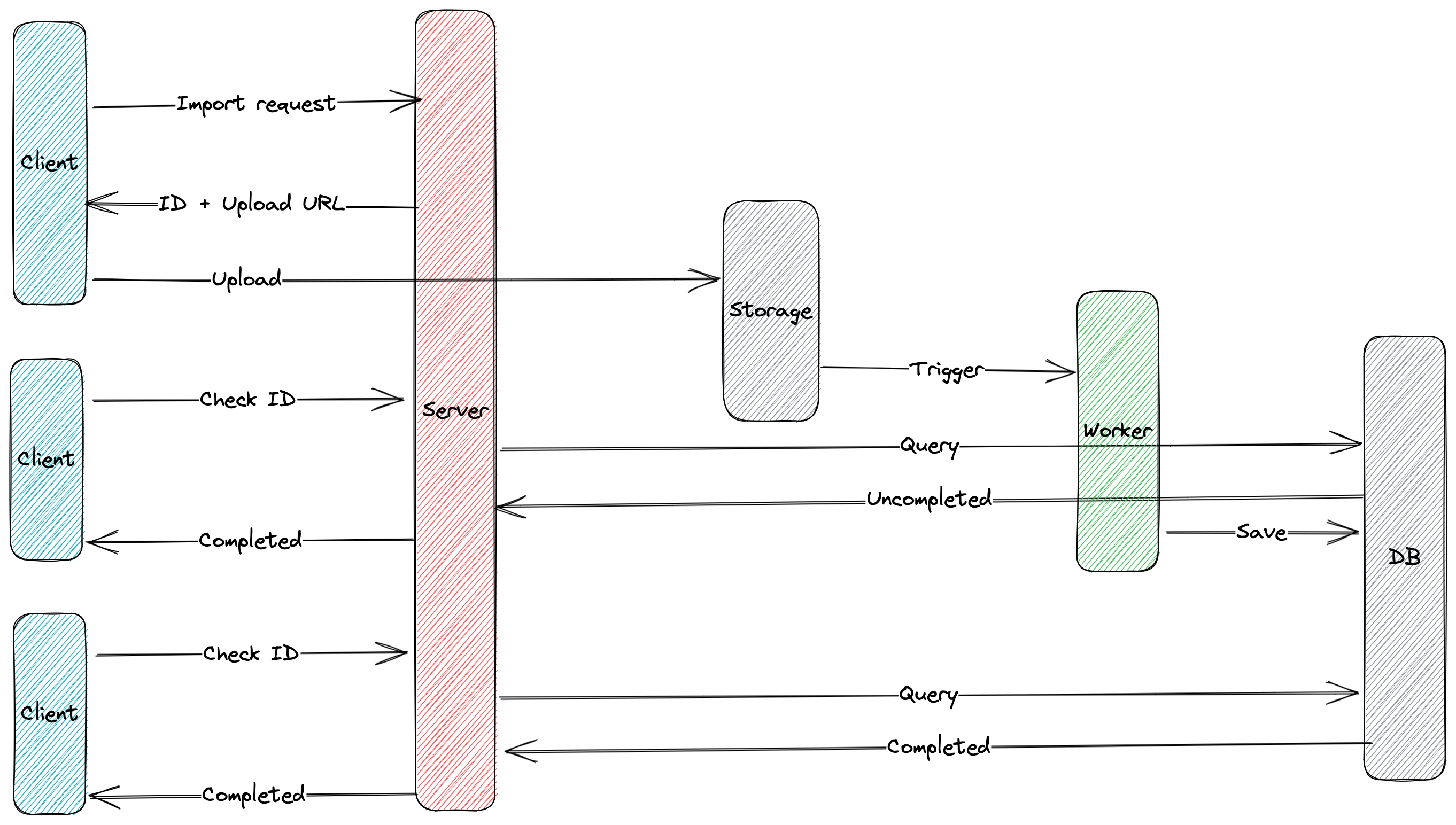
In the following sections, we will go through each step of the workflow, and I will explain in detail what we do in each step.
Request an export task
Simillar to other systems, the client needs to submit their query criteria to request an export task. This request often contains datetime range, column or property filters, sorting criteria and sometimes a limit on number of items to export. Once the server receives the request, it publishes a request task message which contains a unique ID (referred to as the Export ID), to a queue system to allow the worker handle the exporting. Finally we return the Export ID to the client so they can check the task’s status later.
The critical step in this process is delegating the task of collecting and generating data in desired format (e.g., CSV, Excel) to a background job. This task can be resource-intensive and may task a while to complete. Therefore, handling it within the same API can block other processes, especially in a single-threaded programming languge like NodeJS
Handle the export
Collecting and generating data form is specific to each business’s requirements, so it’s up to you to handle it. The crucial factor in this step is having a backend database to store the task’s status, progress and download URL once the export is completed. Choosing the appropriate database should be done carefully as we will be making many requests to database to check the task status.
This step requires making tradeoff decisions based on your business’s requirements. You can answer some questions I list bellow to find out which can be the best fitfor your specific scenario
- Do you need to retry an uncompleted task and show the history of exports? If yes, select a SQL such as PostgreSQL or MySQL
- Is it acceptable to lose the entire database and mark incompleted task as failed requiring user to request another export? If yes, use SQLite.
- You only need a temporary storage for task status and download URL. It is acceptableto lose the task, and you don’t need to show a list of export history. If yes, use Redis as your backend database
I have often found that Redis is the best candidate for this job because not many businesses need to show export history. If we lose the export task, we can inform the user to request another export, and we will generate it for them. Although re-generating wastes resource, it is acceptable because of simplicity of implementation with Redis
Checking task status
As you can see in the diagram, we are using pull model to update task status in the client. Depending on your configuration, the client (i.e., website, iOS or Android app) can make periodic requests to the server to check the task status. If the response indicates the task is not yet completed, we will continue fetching it. Otherwise we will receive a successfull response with a download URL, which the client can use to download the export file, or failed response with an explaination for why we could not generate their export.
Using the pull model with HTTP connections allow us to avoid the cost of real-time connections and reduces the server load during peak time with some tricks. For example, we can return the next delay time to inform the client to wait until that delay has passed before making another request.
Idealy, I often use a concrete delay time, such as 5 seconds. But you can totally use an exponential formula to calculate your delay time. One of my favorite formula is x + Math.log(Math.pow(2, n)) with x being the initial delay time (often 5s) and n being the numer of request you have made.
Technical decisions
It’s important to note that the choice of components in our system heavily depends on your current techstack. Therefore, I can’t provide a one-size-fits-all solution. However, I can offer insights into our use case in the hope of inpsiring you.
In terms of queuing, we decided to go with RabbitMQ due to its widespread usage and ease of deployment on various cloud providers. While we also considered nats.io, RabbitMQ provided us with a safer choice for maintenance.
For our database, we opted for Redis as it fits our use case with its speed and performance. Although we acknowledge the risk of data loss, we found that Redis allows us to recover lost task easily as the way I mentioned before.
In conclusion, we hope that our experiences can be of help to you. Keep in mind that the best choice for your system will depend on your unique circumstances and requirements.